Kafka学习
题记
本文记录对Kafka的入门学习。
Kafka介绍
Kafka是什么
1 | kafka使用scala开发,支持多语言客户端(c++、java、python、go等) |
Kafka的特点
Kafka是分布式的,其所有的构件borker(服务端集群)、producer(消息生产)、consumer(消息消费者)都可以是分布式的。
在消息的生产时可以使用一个标识topic来区分,且可以进行分区;每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。
同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡
常用的场景
监控:主机通过Kafka发送与系统和应用程序健康相关的指标,然后这些信息会被收集和处理从而创建监控仪表盘并发送警告。
消息队列: 应用程度使用Kafka作为传统的消息系统实现标准的队列和消息的发布—订阅,例如搜索和内容提要(Content Feed)。比起大多数的消息系统来说,Kafka有更好的吞吐量,内置的分区,冗余及容错性,这让Kafka成为了一个很好的大规模消息处理应用的解决方案。消息系统 一般吞吐量相对较低,但是需要更小的端到端延时,并尝尝依赖于Kafka提供的强大的持久性保障。在这个领域,Kafka足以媲美传统消息系统,如ActiveMR或RabbitMQ
站点的用户活动追踪: 为了更好地理解用户行为,改善用户体验,将用户查看了哪个页面、点击了哪些内容等信息发送到每个数据中心的Kafka集群上,并通过Hadoop进行分析、生成日常报告。
流处理:保存收集流数据,以提供之后对接的Storm或其他流式计算框架进行处理。很多用户会将那些从原始topic来的数据进行 阶段性处理,汇总,扩充或者以其他的方式转换到新的topic下再继续后面的处理。例如一个文章推荐的处理流程,可能是先从RSS数据源中抓取文章的内 容,然后将其丢入一个叫做“文章”的topic中;后续操作可能是需要对这个内容进行清理,比如回复正常数据或者删除重复数据,最后再将内容匹配的结果返 还给用户。这就在一个独立的topic之外,产生了一系列的实时数据处理的流程。
日志聚合:使用Kafka代替日志聚合(log aggregation)。日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置(文件服务器或HDFS)进行处理。然而Kafka忽略掉 文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让Kafka处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的 系统比如Scribe或者Flume来说,Kafka提供同样高效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟
持久性日志:Kafka可以为一种外部的持久性日志的分布式系统提供服务。这种日志可以在节点间备份数据,并为故障节点数据回复提供一种重新同步的机制。Kafka中日志压缩功能为这种用法提供了条件。在这种用法中,Kafka类似于Apache BookKeeper项目。
Kafka中包含以下基础概念
1 | 1.Topic(话题):Kafka中用于区分不同类别信息的类别名称。由producer指定 |
消息
消息由一个固定大小的报头和可变长度但不透明的字节阵列负载。报头包含格式版本和CRC32效验和以检测损坏或截断
消息格式
1 | 1. 4 byte CRC32 of the message |
Kafka深层介绍
架构介绍
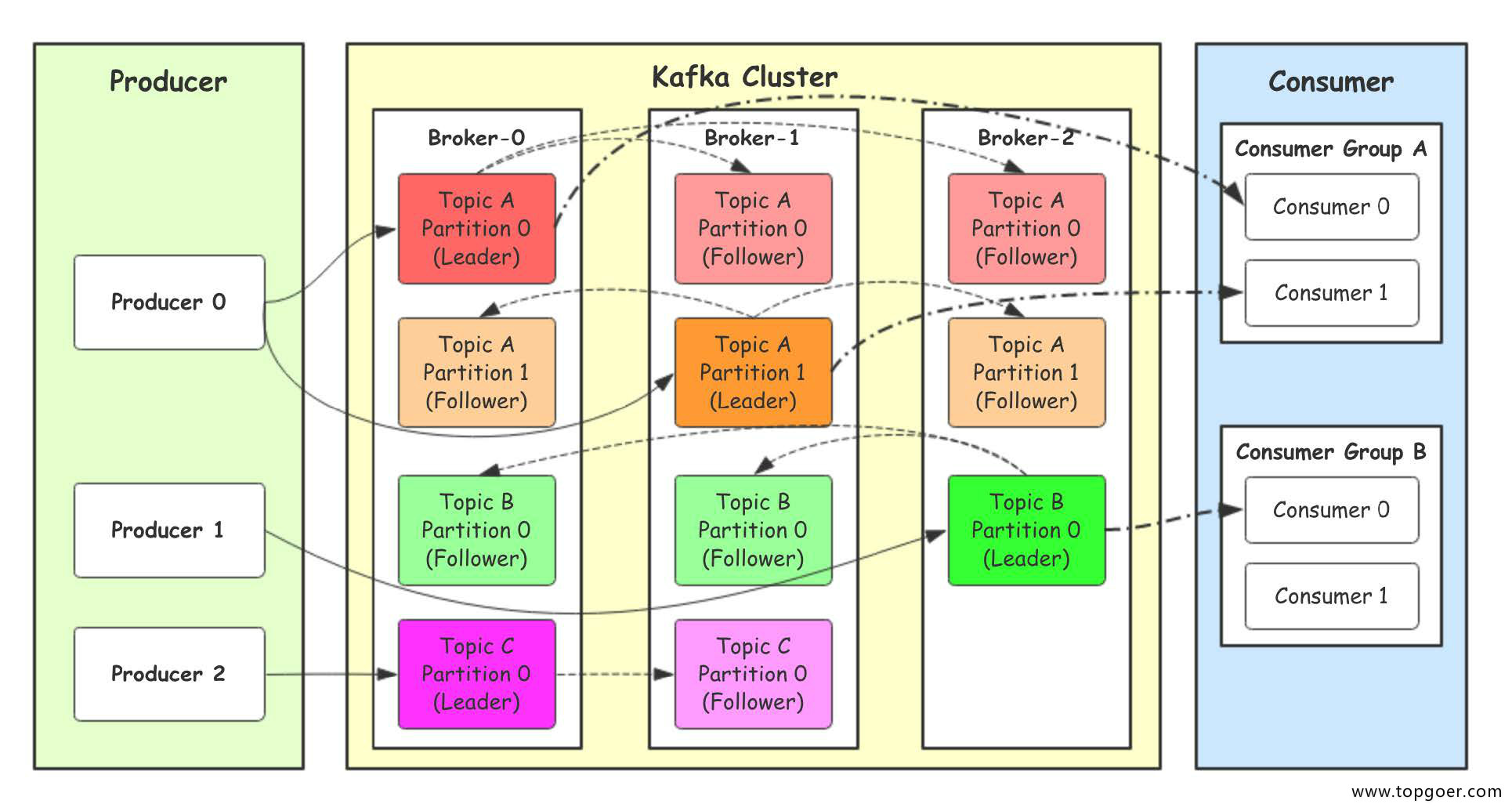
- Producer:Producer即生产者,消息的产生者,是消息的⼊口。
- kafka cluster:kafka集群,一台或多台服务器组成
- Broker:Broker是指部署了Kafka实例的服务器节点。每个服务器上有一个或多个kafka的实 例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的 编号,如图中的broker-0、broker-1等……
- Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上 都可以创建多个topic。实际应用中通常是一个业务线建一个topic。
- Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞 吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的⽂件夹!
- Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的 时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10 个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机 器对同一个分区也只可能存放一个副本(包括自己)。
- Consumer:消费者,即消息的消费方,是消息的出口。
- Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分 区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个 topic的不同分区的数据,这也是为了提高kafka的吞吐量!
⼯作流程
我们看上⾯的架构图中,producer就是生产者,是数据的入口。Producer在写入数据的时候会把数据 写入到leader中,不会直接将数据写入follower!那leader怎么找呢?写入的流程又是什么样的呢?我 们看下图:
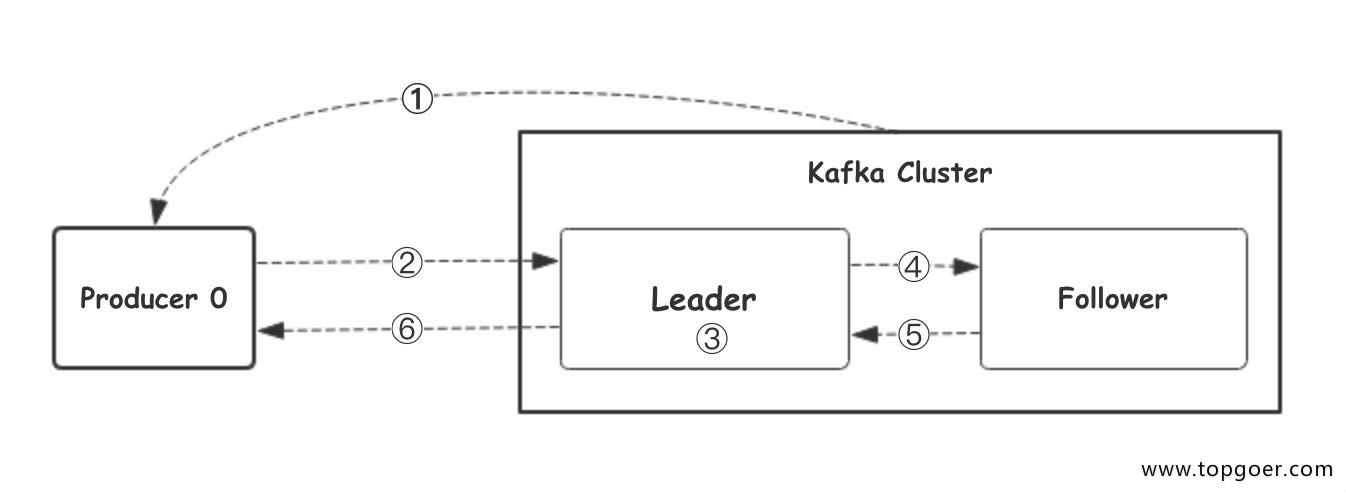
1 | 1.⽣产者从Kafka集群获取分区leader信息 |
选择partition的原则
那在kafka中,如果某个topic有多个partition,producer⼜怎么知道该将数据发往哪个partition呢? kafka中有几个原则:
1 | 1.partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。 |
ACK应答机制
producer在向kafka写入消息的时候,可以设置参数来确定是否确认kafka接收到数据,这个参数可设置 的值为 0,1,all
- 0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效 率最高。
- 1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
- all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保 leader发送成功和所有的副本都完成备份。安全性最⾼高,但是效率最低。
最后要注意的是,如果往不存在的topic写数据,kafka会⾃动创建topic,partition和replication的数量 默认配置都是1。
Topic和数据⽇志
topic 是同⼀类别的消息记录(record)的集合。在Kafka中,⼀个主题通常有多个订阅者。对于每个 主题,Kafka集群维护了⼀个分区数据⽇志⽂件结构如下:
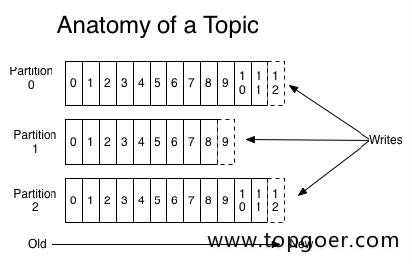
每个partition都是⼀个有序并且不可变的消息记录集合。当新的数据写⼊时,就被追加到partition的末 尾。在每个partition中,每条消息都会被分配⼀个顺序的唯⼀标识,这个标识被称为offset,即偏移 量。注意,Kafka只保证在同⼀个partition内部消息是有序的,在不同partition之间,并不能保证消息 有序。
Kafka可以配置⼀个保留期限,⽤来标识⽇志会在Kafka集群内保留多⻓时间。Kafka集群会保留在保留 期限内所有被发布的消息,不管这些消息是否被消费过。⽐如保留期限设置为两天,那么数据被发布到 Kafka集群的两天以内,所有的这些数据都可以被消费。当超过两天,这些数据将会被清空,以便为后 续的数据腾出空间。由于Kafka会将数据进⾏持久化存储(即写⼊到硬盘上),所以保留的数据⼤⼩可 以设置为⼀个⽐较⼤的值。
Partition结构
Partition在服务器上的表现形式就是⼀个⼀个的⽂件夹,每个partition的⽂件夹下⾯会有多组segment ⽂件,每组segment⽂件⼜包含 .index ⽂件、 .log ⽂件、 .timeindex ⽂件三个⽂件,其中 .log ⽂ 件就是实际存储message的地⽅,⽽ .index 和 .timeindex ⽂件为索引⽂件,⽤于检索消息。
消费数据
多个消费者实例可以组成⼀个消费者组,并⽤⼀个标签来标识这个消费者组。⼀个消费者组中的不同消 费者实例可以运⾏在不同的进程甚⾄不同的服务器上。
如果所有的消费者实例都在同⼀个消费者组中,那么消息记录会被很好的均衡的发送到每个消费者实 例。
如果所有的消费者实例都在不同的消费者组,那么每⼀条消息记录会被⼴播到每⼀个消费者实例。
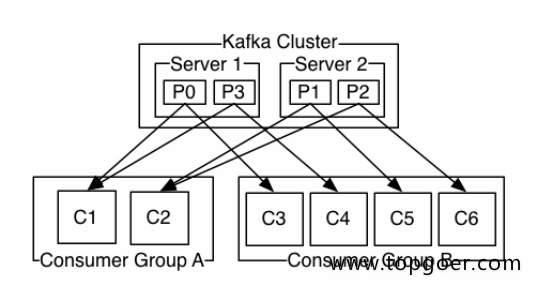
举个例⼦,如上图所示⼀个两个节点的Kafka集群上拥有⼀个四个partition(P0-P3)的topic。有两个 消费者组都在消费这个topic中的数据,消费者组A有两个消费者实例,消费者组B有四个消费者实例。 从图中我们可以看到,在同⼀个消费者组中,每个消费者实例可以消费多个分区,但是每个分区最多只 能被消费者组中的⼀个实例消费。也就是说,如果有⼀个4个分区的主题,那么消费者组中最多只能有4 个消费者实例去消费,多出来的都不会被分配到分区。其实这也很好理解,如果允许两个消费者实例同 时消费同⼀个分区,那么就⽆法记录这个分区被这个消费者组消费的offset了。如果在消费者组中动态 的上线或下线消费者,那么Kafka集群会⾃动调整分区与消费者实例间的对应关系。
Kafka安装
我个人喜欢直接将Kafka安装到docker上,所以我这里的安装教程也是docker下的Kafka安装。
第一步:使用下述命令从Docker Hub查找镜像,此处我们要选择的是zookeeper官网的镜像
1 | docker search zookeeper |
第二步:拉取zookeeper镜像
1 | docker pull wurstmeister/zookeeper:latest |
第三步:启动zookeeper容器
1 | docker run -d --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime wurstmeister/zookeeper |
-v /etc/localtime:/etc/localtime 容器时间同步虚拟时间

第四步:拉取Kafka镜像,此处选择的是 wurstmeister/kafka (这个镜像的受欢迎程度最高)
1 | docker pull wurstmeister/kafka:latest |
第五步:如果是在Windows系统中可以使用下述命令启动kafka容器
1 | docker run -d --name Kafka --publish 9092:9092 --link zookeeper --env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 --env KAFKA_ADVERTISED_HOST_NAME=localhost --env KAFKA_ADVERTISED_PORT=9092 wurstmeister/kafka |

第六步:使用下述命令进入都kafka容器内部,然后进入到 /opt/kafka_2.13-2.8.1/bin 目录下
1 | docker exec -it 容器id bash |
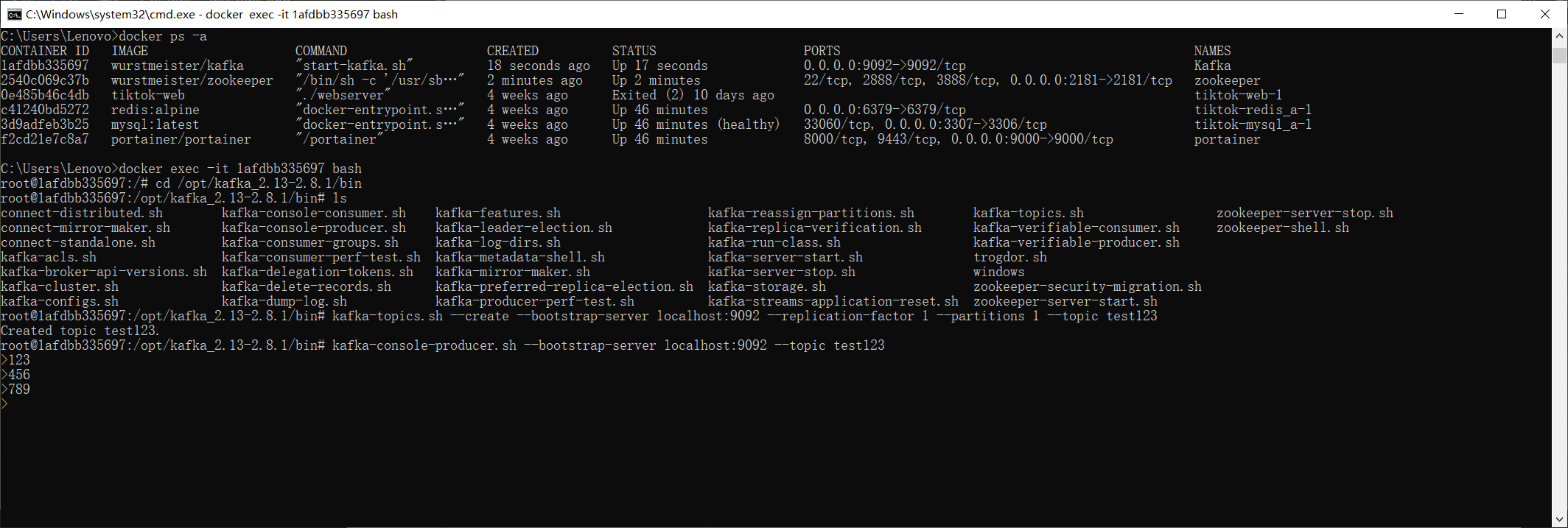
第七步:使用下述命令创建一个单分区单副本的主题 “test123”,并且创建生产者生产消息
1 | kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test123 |

接着另起一个连接创建消费者接收消息:
1 | kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test123 --from-beginning |
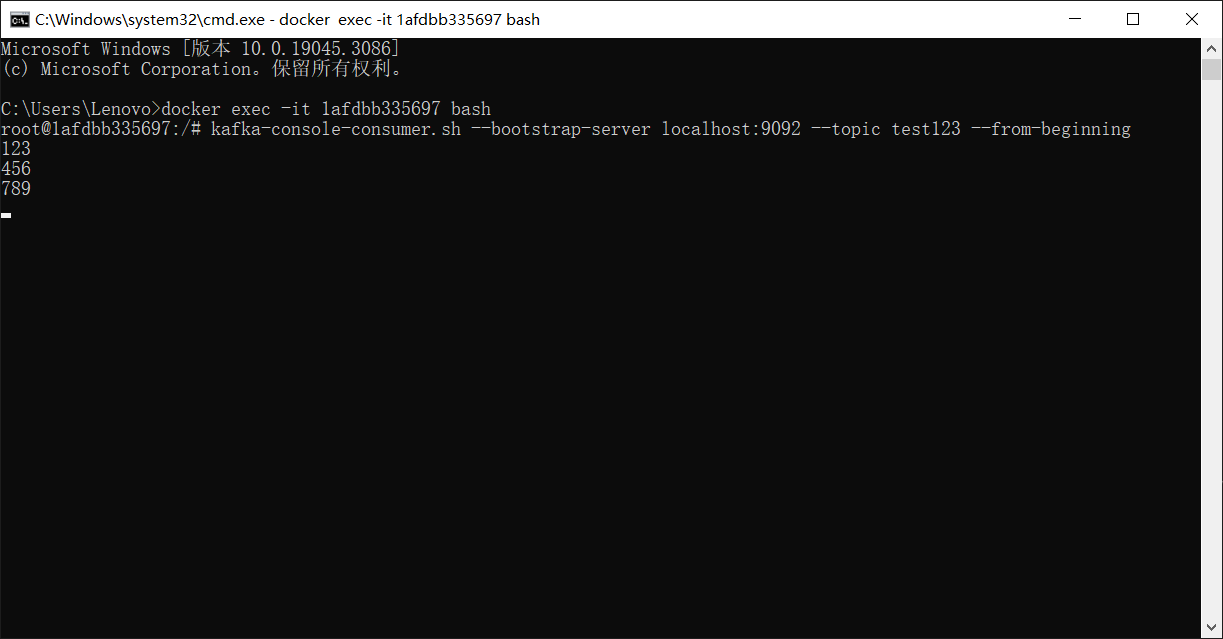
操作Kafka
1 | go get github.com/segmentio/kafka-go |
连接kafka发送消息
1 | package main |
连接kafka消费消息
1 | package main |
输出:
1 | message at topic/partition/offset test/0/6: Key-A = Hello World! |
消息队列面试题
为什么要使用消息队列?
总结一下,主要三点原因:解耦、异步、削峰。
1、解耦。比如,用户下单后,订单系统需要通知库存系统,假如库存系统无法访问,则订单减库存将失败,从而导致订单操作失败。订单系统与库存系统耦合,这个时候如果使用消息队列,可以返回给用户成功,先把消息持久化,等库存系统恢复后,就可以正常消费减去库存了。
2、异步。将消息写入消息队列,非必要的业务逻辑以异步的方式运行,不影响主流程业务。
3、削峰。消费端慢慢的按照数据库能处理的并发量,从消息队列中慢慢拉取消息。在生产中,这个短暂的高峰期积压是允许的。比如秒杀活动,一般会因为流量过大,从而导致流量暴增,应用挂掉。这个时候加上消息队列,服务器接收到用户的请求后,首先写入消息队列,如果消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面。
使用了消息队列会有什么缺点
- 系统可用性降低。引入消息队列之后,如果消息队列挂了,可能会影响到业务系统的可用性。
- 系统复杂性增加。加入了消息队列,要多考虑很多方面的问题,比如:一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。
如何避免消息重复消费?
在消息生产时,MQ内部针对每条生产者发送的消息生成一个唯一id,作为去重和幂等的依据(消息投递失败并重传),避免重复的消息进入队列。
在消息消费时,要求消息体中也要有一全局唯一id作为去重和幂等的依据,避免同一条消息被重复消费。
多线程异步和MQ的区别
- CPU消耗。多线程异步可能存在CPU竞争,而MQ不会消耗本机的CPU。
- MQ 方式实现异步是完全解耦的,适合于大型互联网项目。
- 削峰或者消息堆积能力。当业务系统处于高并发,MQ可以将消息堆积在Broker实例中,而多线程会创建大量线程,甚至触发拒绝策略。
- 使用MQ引入了中间件,增加了项目复杂度和运维难度。
总的来说,规模比较小的项目可以使用多线程实现异步,大项目建议使用MQ实现异步。
MQ 中的消息过期失效了怎么办?
如果使用的是RabbitMQ的话,RabbtiMQ 是可以设置过期时间的(TTL)。如果消息在 Queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。这时的问题就不是数据会大量积压在 MQ 里,而是大量的数据会直接搞丢。这个情况下,就不是说要增加 Consumer 消费积压的消息,因为实际上没啥积压,而是丢了大量的消息。
我们可以采取一个方案,就是批量重导。就是大量积压的时候,直接将数据写到数据库,然后等过了高峰期以后将这批数据一点一点的查出来,然后重新灌入 MQ 里面去,把丢的数据给补回来。
大量消息在 MQ 里长时间积压,该如何解决?
一般这个时候,只能临时紧急扩容了,具体操作步骤和思路如下:
- 先修复 consumer 的问题,确保其恢复消费速度,然后将现有 consumer 都停掉;
- 新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量;
- 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue;
- 接着临时用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据;
- 等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
- 标题: Kafka学习
- 作者: Olivia的小跟班
- 创建于 : 2023-06-27 14:29:17
- 更新于 : 2023-07-19 13:52:38
- 链接: https://www.youandgentleness.cn/2023/06/27/Kafkaѧϰ/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。